


En los primeros días de la computación, las máquinas solo podían ejecutar un programa a la vez, lo que hacía que diseñar programas fuera muy lento. Los usuarios tenían sus programas y datos en tarjetas perforadas o cintas magnéticas, cargaban el programa, lo ejecutaban, lo depuraban y, finalmente, recogían los resultados. Desarrollar y probar software en esas condiciones era muy tedioso y complejo.

Con el tiempo, se desarrollaron sistemas que podían procesar un conjunto de programas en batches o “lotes” que se escribían en una misma cinta magnética. El computador leía la cinta y ejecutaba una instrucción tras otra, mejorando un poco la eficiencia, pero el proceso seguía siendo lento. El tiempo de respuesta tomaba días enteros. Si tenías mucha suerte, podían ser horas. Ni hablar de una respuesta en tiempo real.
Hoy los computadores pueden ejecutar millones de programas en paralelo, lo que permite desarrollar y probar mucho más rápido tu código. Esto ha permitido un ciclo de desarrollo mucho más rápido y eficiente.
En Fintoc creemos que el avance de producto debería ser tan rápido como la tecnología actual lo permite.
Cualquier roce que te impide desarrollar o salir a producción es un problema gigante a arreglar y, por lo mismo, hemos invertido harto tiempo en mejorar la experiencia de desarrollo del equipo. Cada pull request que está listo y no estamos pasando a producción es tiempo que no estamos generando valor para nuestros usuarios.
Pasamos a producción entre 6 y 9 veces al día. Nos gusta ir rápido, sin romper cosas entremedio, y tratamos de que sea lo más fácil posible. Llegar a este ritmo de deploys fue un proceso que implicó varias mejoras. Acá te cuento las automatizaciones y bots que armamos para que cosas como revisar PRs y hacer deploys sean lo más fácil y rápido posible.
Primeros pasos
El primer paso para deployear rápido es que el proceso de revisión de PRs sea fácil.
Para lograr esto, cada vez que subes un PR a Github una Github Action asigna automáticamente un label a ese PR con el tamaño. Los labels van de size/XS hasta size/XXL. Definimos que si un PR es size/XL o size/XXL los reviewers pueden pedirte (sin revisar el PR) que los separes para que sea más rápido y fácil de revisar.
Entre más corto el PR, más fácil entender todo y revisar cada línea de código con más detalle. Si el PR es muy largo, el reviewer necesita más tiempo para revisarlo, y el owner más tiempo para arreglar los comentarios. Además, si pasas PRs pequeños a producción, es más fácil encontrar bugs y hacer reverts.

Una vez que subes tu PR, tenemos un bot que automáticamente asigna dos reviewers. Así el owner del PR no tiene que usar ciclos de CPU en pensar a quién pedirle el review.
Muchos PRs chicos = mucho que mergear
Con el equipo sacando PRs más pequeños, llegamos a tener entre 20 y 30 PRs por día. Esto nos trajo un problema: mergearlos se volvió más lento de lo que debería.
Funcionamos usando Continuous Integration, donde corremos todos los tests de Fintoc, además de hacer el build de la imagen de producción, correr migraciones y más. A veces este proceso de varias etapas toma mucho tiempo. Pese a que siempre lo estamos optimizando, cada PR tiene que correr el CI completo (que pueden ser más de 10 minutos) y, si alguien mergea antes que tú, tu PR debe hacer rebase y volver a correr todo el CI de nuevo (esto es por el problema de Semantic Conflict al usar branches de Git).
Lo solucionamos implementando una merge queue: una cola de PRs que va mergeando automáticamente. Le pusimos Fintoneta (como la Scaloneta) y solo necesitamos comentar fin merge en el PR para que empiece el proceso. Este bot se encarga de actualizar el PR si es necesario, correr el CI y mergear a la rama principal si es que pasan los tests. Si hay conflictos con la actualización, le avisa al dev para que lo arregle.

Otro problema, otro bot
Usamos los issues de Linear para organizar nuestro flujo de trabajo, pero es una lata mover las tarjetas cuando un PR se mergea o pasa a producción.
Por lo mismo, hace más de dos años comenzamos a poner el identificador de la tarea de Linear (un tag como [INF-972]) en los títulos de los PRs para que un bot que hicimos asocie el PR a la tarjeta. Además, a medida que el ciclo de vida del PR avanza y pasa por las etapas in-progress, in-review, staging y producción , el bot va moviendo las tarjetas por su cuenta (no era mala idea, Linear desarrolló esa feature y ya es parte de su app). Con esto, le quitamos la pega manual al dev de actualizar Linear.
Si bien intentamos automatizar todo lo que podemos, no todo se puede automatizar. Tenemos que testear mucho el código y eso implica que varias veces tenemos que hacer algunas pruebas manuales o sensibles y para eso usamos el ambiente de staging.
Un dev puede “tomarse” staging para hacer pruebas. Esto implica que nadie debería hacer deploy, por que no quiere que su código pase a producción antes de terminar de hacer alguna prueba y que libere staging.
Para esto un dev avisaba por Slack que iba a usar staging, rápidamente lo automatizamos a través de un bot. Solo necesitabas decirle qué repositorio querías bloquear y él le avisaba a los devs.
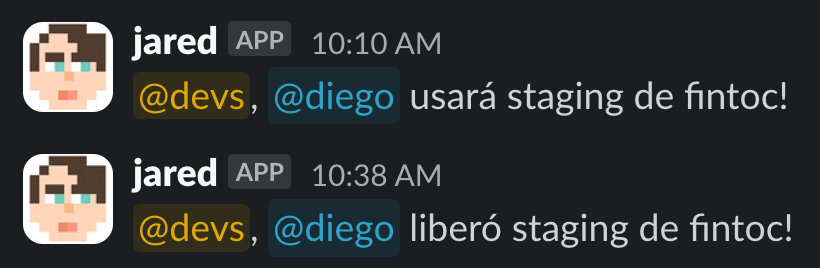
Funcionaba bien, pero aún quedaban dos problemas a mejorar:
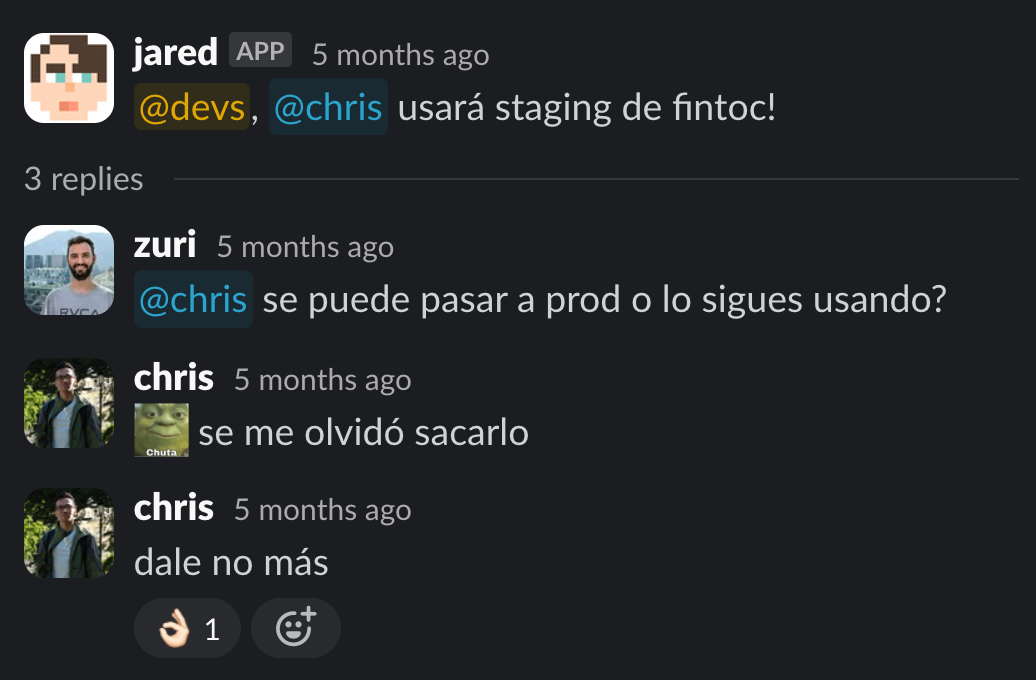
Notificaba a todo el equipo de ingeniería y les pedía que no pasaran a producción, pero realmente no bloqueaba el pipeline de deploy. Si un dev no veía el mensaje, igual podía hacer deploy y el aviso no servía de nada.
Se te podía olvidar “liberar” staging y por lo mismo afectaba el desarrollo de otros devs: Fuimos creciendo el equipo, sacando muchos PRs y terminó convirtiéndose en un dolor deployear y probar cosas en staging, así que decidimos armar nuestro bot de developer experience, Gilfoyle.
Nace Gilfoyle
Creamos a Gilfoyle, un bot cuyo nombre viene de nuestros personajes favoritos de la serie Silicon Valley (muy recomendada si no te la tomas muy en serio) y le dimos hartas atribuciones para que todas las etapas de pasar a producción sean lo más smooth posible.
Incluye nuevos features para dar más contexto a los PRs y a los deploys, además de mejorar cómo bloqueamos y desbloqueamos los repositorios. También da mayor visibilidad a los cambios que se están haciendo en todos los proyectos de Fintoc.
Clasificador de PRs
Cada vez que se crea un pull request, aparte de agregar el label del tamaño, Gilfoyle revisa qué archivos toca y le agrega labels para dar más contexto.

Los labels que creamos son:
migration: este PR implica cambios al modelo de la base datosinternal-api: hay cambios a los serializadores entre servicios internos de Fintocpublic-api: hay cambios a la API de los clientesinfra: los cambios tocan archivos de configuración de infraestructura como Terraform, Kubernetes u otros
Además, lo hicimos genérico para que a medida que vayamos creciendo o verlo necesario, agregar nuevos labels sea muy fácil. Basta con agregar una regla de regex nueva al clasificador.
Deployear desde cualquier parte
Por supuesto, Gilfoyle te permite deployear desde Slack. Para incentivar el deploy, y apuntando a que deployear en Fintoc sea muy fácil desde el día 1, creamos deploy <repo> , un comando que te avisa qué PRs puedes deployear en el repo seleccionado y te permite deployear a través de una interfaz muy rápida. Tanto así, que incluso puedes hacer un deploy desde tu celular.

@gilfoyle deploy repo
Gilfoyle avisa siempre que se hace un deploy en staging y producción. Cada vez que un PR es mergeado y su deploy termina, se avisa en un canal. Esta notificación primero avisa si hay un deploy en curso y luego actualiza el mensaje para notificar el estado final. Cuando el deploy a staging es exitoso se ve así:
Otras cositas que le fuimos agregando al bot:
- Avisa cuando un deploy falló con un link al PR.
- Usa los labels del PR para mostrar un emoji con la naturaleza del PR para que sea fácil identificar PRs críticos (como el del arriba 🐘 que tiene una migración a la base de datos)
- Le avisa a los responsables del PR si se logró deployear o no
Incentivando a deployear
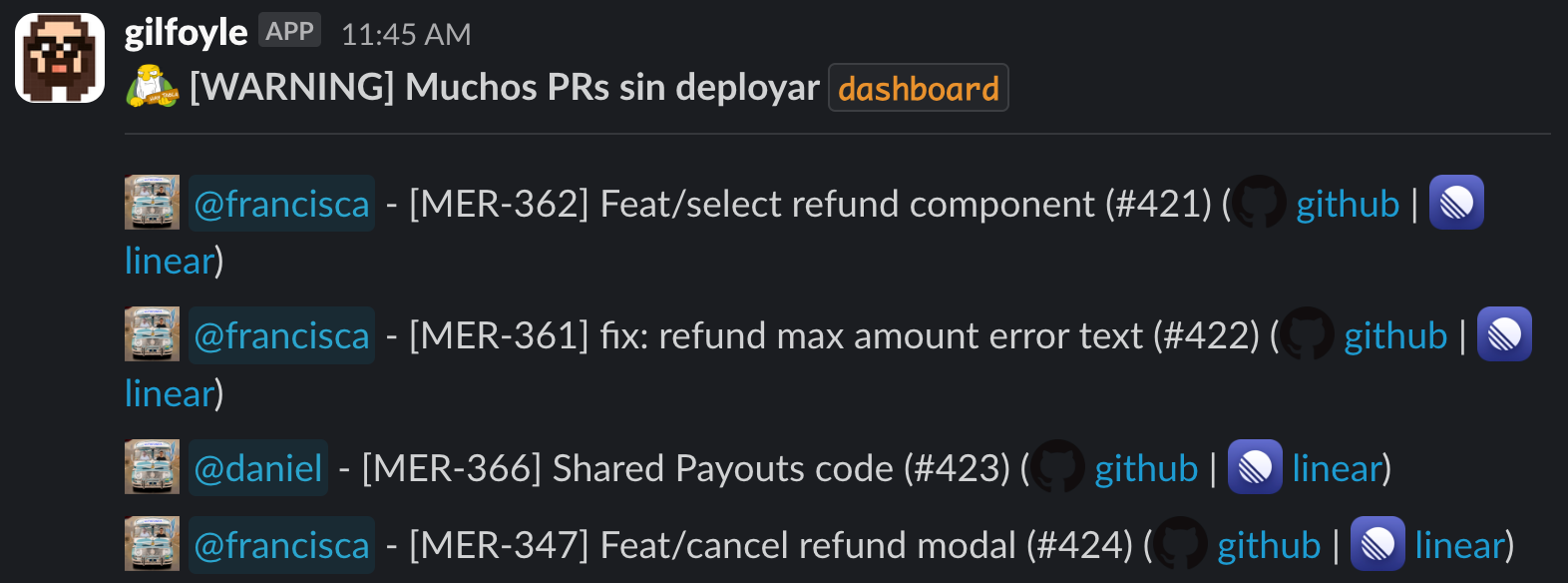
Gilfoyle también revisa la cantidad de PRs acumulados en staging y, si hay más de 4 pendientes, emite una alerta que te empuja a hacer un deploy.
Si estás pasando mucho código a producción constantemente corres el riesgo de que las cosas se rompan. Entre más cambios pequeños haces, mejor, porque es más fácil identificar qué se rompió y arreglarlo rápido.
Si, por ejemplo, deployeas 10 PRs de una, cualquiera de esos 10 puede fallar y tendrías que revisarlos todos para encontrar qué pasó. En cambio, si estás deployeando cada 1 o 2 PRs, se mitigan muchos de esos riesgos y hay más control para monitorear que todo está funcionando ok en producción. Además, hace que un rollback sea mucho más fácil de ejecutar.
@gilfoyle bloquear repo
En Fintoc, si tu código está en staging, es deployeable a producción. Cualquiera lo puede hacer y es tu responsabilidad hacerte cargo si no quieres que pase a producción.
Gilfoyle te permite bloquear y desbloquear un repositorio si estás probando cosas sensibles en staging, así nadie sube tu código a producción sin tu permiso. Así, si tienes que probar algo crítico en staging, puedes bloquear deploy <repo> y le avisa a todos que estás ocupando ese repositorio, además desactiva la deploy station y nadie puede deployear hasta que desbloquees ese repositorio. (Esto también lo puedes configurar desde el PR agregando un label de forma manual block-deploy)
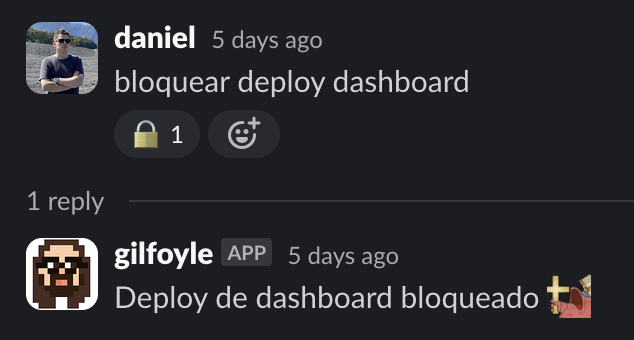
Eso sí, cada cierto tiempo te recuerda que lo tienes bloqueado (para que no pase mucho tiempo) y también te avisa si otra persona está intentando pasar a producción para que te apures 😉
También marca con un ✅ si ya está desbloqueado para dar más contexto a cualquiera que lea el mensaje.
Should I deploy today?
La cultura de ingeniería de Fintoc se trata de avanzar rápido y hacer las cosas bien.
Estas herramientas nos gustan mucho porque, además de darle visibilidad al trabajo propio y de los demás, es una muestra de esta mentalidad. Apuntamos a que un dev pueda deployear lo más rápido posible desde que entra a Fintoc. De hecho, Felipe (el último dev que entró a Fintoc) pasó a producción 5 veces y mergeó 11 PRs en sus primeras 2 semanas.
Con estas y otras herramientas parecidas, logramos alcanzar un promedio de 9 deploys al día y entre 20 y 30 PRs a producción diarios, con apenas 14 devs en el equipo.
Y si a alguien le baja el miedo o le falta motivación, hice https://shouldideploy.fintoc.com/

Crecer el equipo no necesariamente implica ir más lento y es algo que tenemos en mente todo el tiempo. Crecer el equipo debería significar ir más rápido, lo que nos obliga a seguir invirtiendo en mejorar los procesos y las herramientas de ingeniería todo el tiempo.








