
%201.48.58%E2%80%AFp.m..png)
.png)

How we scaled our infrastructure to handle millions of requests to financial institutions

Scaling Challenges
At Fintoc, we follow the philosophy of always designing with simplicity in mind (KISS). This helps us move fast while also ensuring our software remains maintainable and understandable for all developers.
However, as we scale, solutions inevitably become more complex because the assumptions of the original design no longer hold.
The Challenge: Scale
Today, we handle more than 4,000,000 daily requests generated by payment jobs and bank statement updates. For some financial institutions, this meant a 5x increase in requests compared to the beginning of the year.
Each of these processes requires different infrastructure:
- For payments, we need speed because the user interacts with our widget in real-time.
- For bank statement updates, we need high computing power and efficient algorithms to process large amounts of data.
But they both share one common aspect: the massive number of requests we must send to financial institutions, which naturally led to problems.
In this post, I’ll refer to both payment processing and account updates as jobs.
Restrictions
The financial institutions we interact with have implemented security measures to prevent malicious overloads, and despite our agreements, these restrictions still apply to us.
One of the most critical security measures is Rate Limiting, which restricts the amount of traffic to a website. This can be implemented in different ways, but the most common is by IP—if too many requests come from the same IP, access is blocked for a configurable period.
Faced with this limitation, we had to design a way to maintain our scale while adapting to these restrictions.
Distributing Traffic Across Multiple IPs
Since the main restriction is at the IP level, the question became:
How do we distribute traffic across multiple IPs?
The answer: by using multiple outgoing IPs.
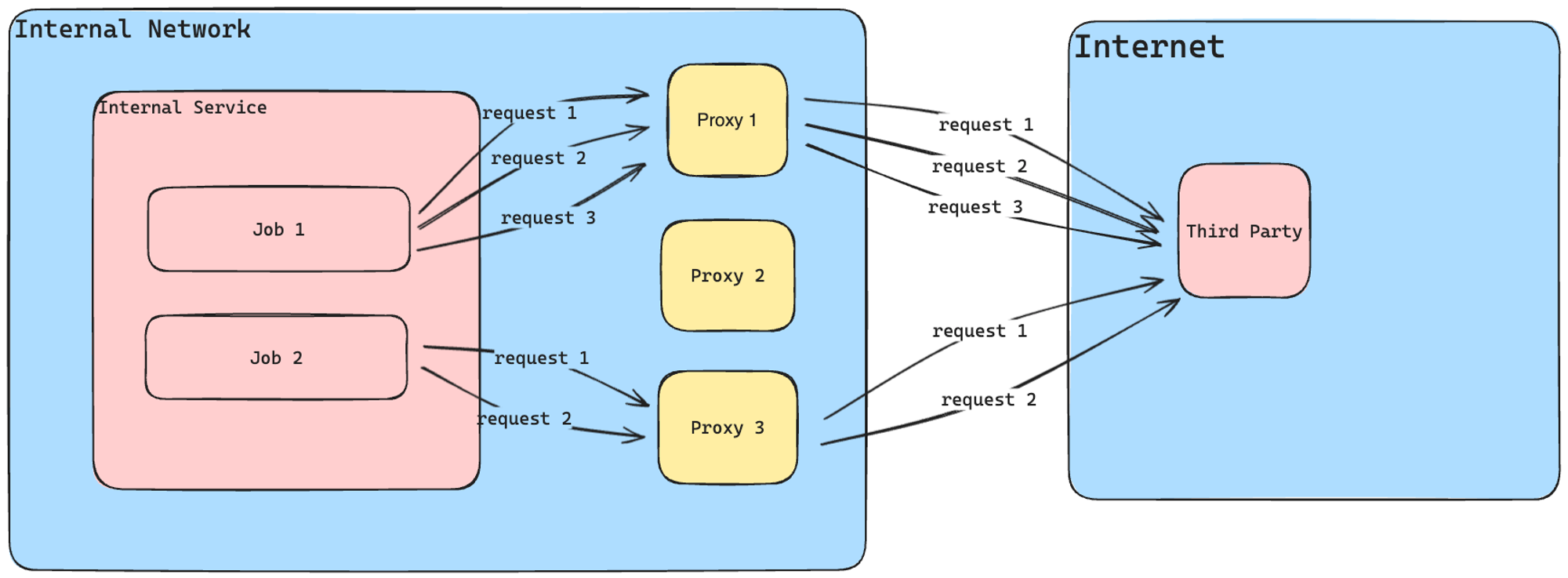
To achieve this, we use proxies. A proxy is, in simple terms, a server that intercepts requests before redirecting them to the target website:
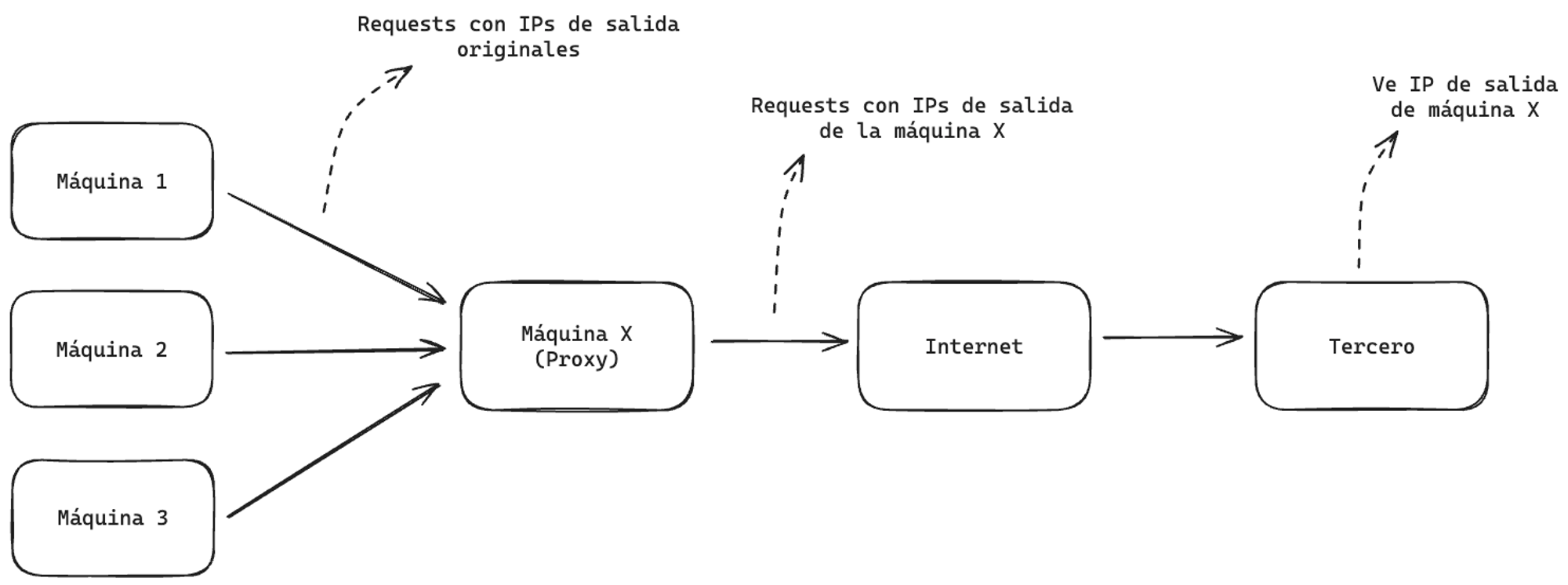
By adding this intermediary, the third-party service only sees the proxy’s IP. If we have many proxies, we have many IPs to distribute our requests across.
Proxy Pool: Same Job, Same IP
One key requirement was that all requests for the same job (or session) on a third-party website must use the same IP to avoid communication issues during the process.
To achieve this, we deployed an HTTP/HTTPS proxy server (using Tinyproxy) on multiple Compute Engine virtual machines (VMs), each assigned an ephemeral external IP and a fixed internal IP.
With both IPs, we could:
- Communicate our internal services with the proxy via our private network (our services are not exposed to the internet).
- Send requests to third-party services through the proxy over the internet.
This setup allowed each job to have a fixed external IP—we simply had to select one of the available internal IPs and route all requests for that job through it.
Performance: Load Distribution
With proxies in place, we needed a mechanism to distribute traffic across them while enforcing certain rules. The key requirements were:
- Proxies should be exclusive to specific job types.
- Example: Use proxies X and Y only for payment jobs to institution Z.
- A denylist for proxies by job type (the opposite of the previous rule).
- Example: Do not use proxies X and Y for bank statement jobs from institution Z.
Even proxy distribution—avoiding overloading some proxies while others remain idle.
To manage these restrictions, we needed an entity that could decide which proxies to assign based on the job context.
To define restrictions, we created database models (using PostgreSQL) representing both proxies and their constraints. This allowed developers and other teams to modify them easily via an internal dashboard.
Each proxy had a status attribute (running, deleted, etc.). These states not only provided real-time information but also helped us handle edge cases (which we'll discuss later).
Circular Proxy Selection
To ensure even usage of proxies, we implemented a circular list containing the database IDs of all proxies. Every time a job starts, it takes a proxy ID from the list and adds it back at the end, ensuring that no proxy is reused until all others have been used at least once.
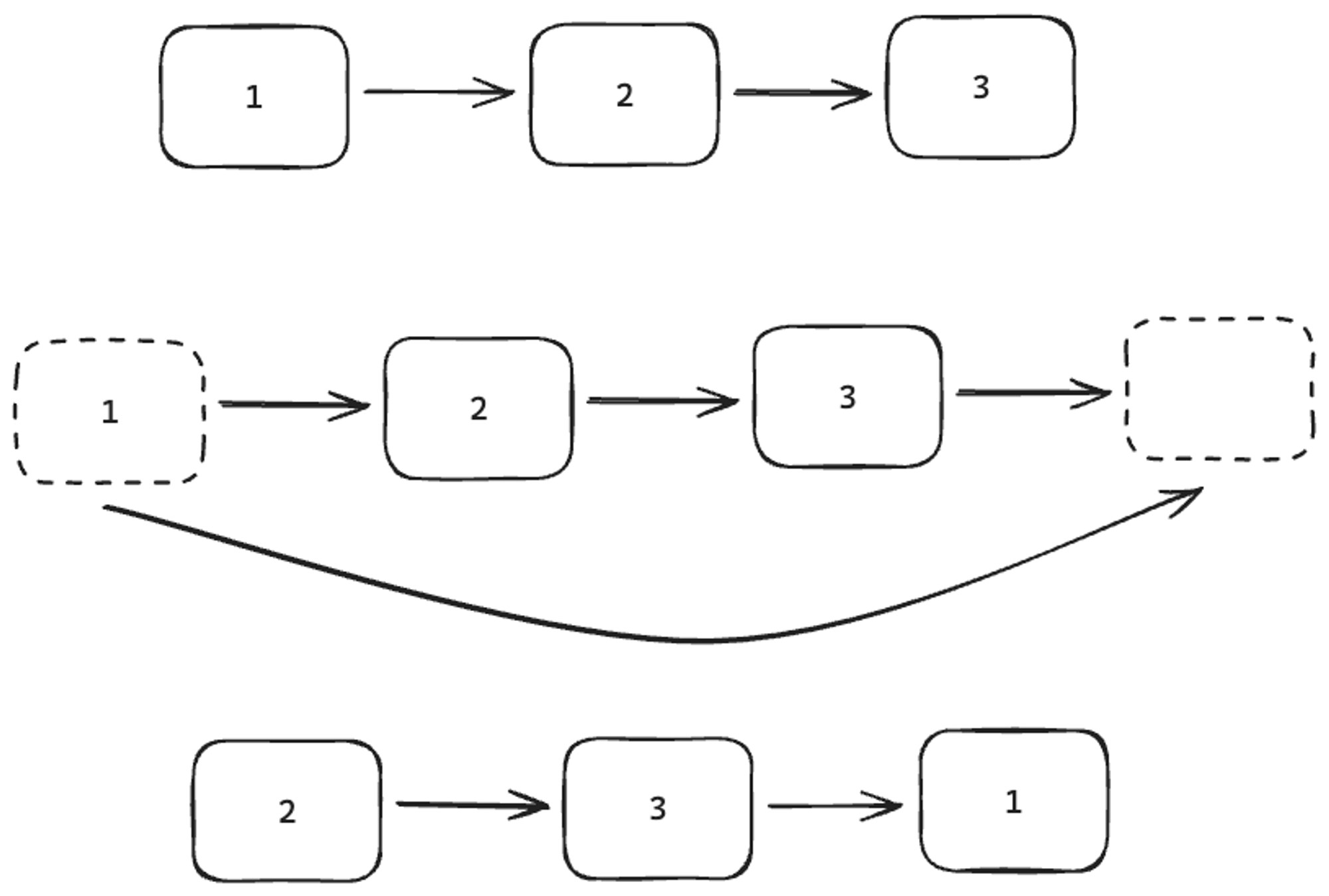
The best tool for this was Redis, which is fast and supports Linked Lists, allowing us to efficiently perform:
LPOP(remove first element)RPUSH(add element to the end)
By combining Redis with PostgreSQL, we had a solid system:
- PostgreSQL stored proxies and their restrictions.
- Redis stored rotation lists for proxies (referenced by their database IDs).
This setup ensured synchronized data sources, and every time a job needed a proxy, it could fetch one from Redis:
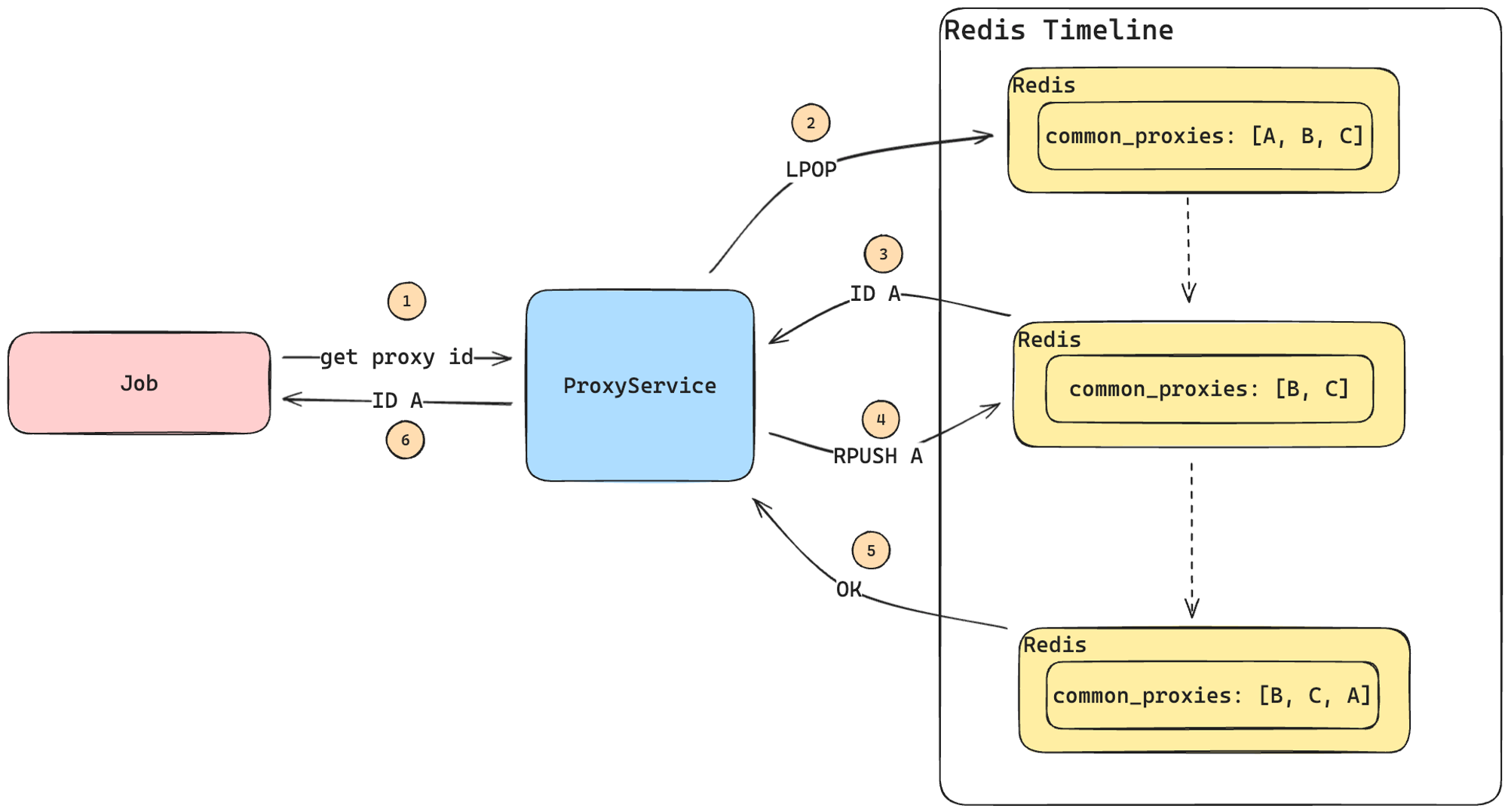
The process would be as follows:
- The job requests a proxy from the ProxyService (note that this is a code module, not a microservice).
- ProxyService retrieves a proxy ID from the common list (key
common_proxies) and adds it back to the end of the list. We call this action rotating a proxy. - ProxyService responds to the job with the selected proxy ID, allowing the job to fetch the necessary information from PostgreSQL.
The selected proxy ID (A) will not be reused until all other proxies in the list have been used at least once.
Infrastructure Management
With this setup, we could create a proxy in both Compute Engine and PostgreSQL, and Redis would update automatically.
To react quickly to traffic spikes, we automated proxy lifecycle management across Compute Engine and our databases. We focused on two key operations:
- Creating a proxy
- Deleting a proxy
Both operations had details that required careful handling, but we’ll focus on deletion:
- Remove the proxy from PostgreSQL
- Remove it from Redis
- Delete it from Compute Engine
The challenge was doing this without disrupting thousands of running jobs—a process more complex than it seems.
Concurrency and Atomicity
To handle Fintoc’s scale, we parallelize jobs, which means multiple jobs could be modifying the same resources at the same time, leading to unexpected race conditions.
Consider this example where one process rotates a proxy while another process deletes it using LPOP and RPUSH:
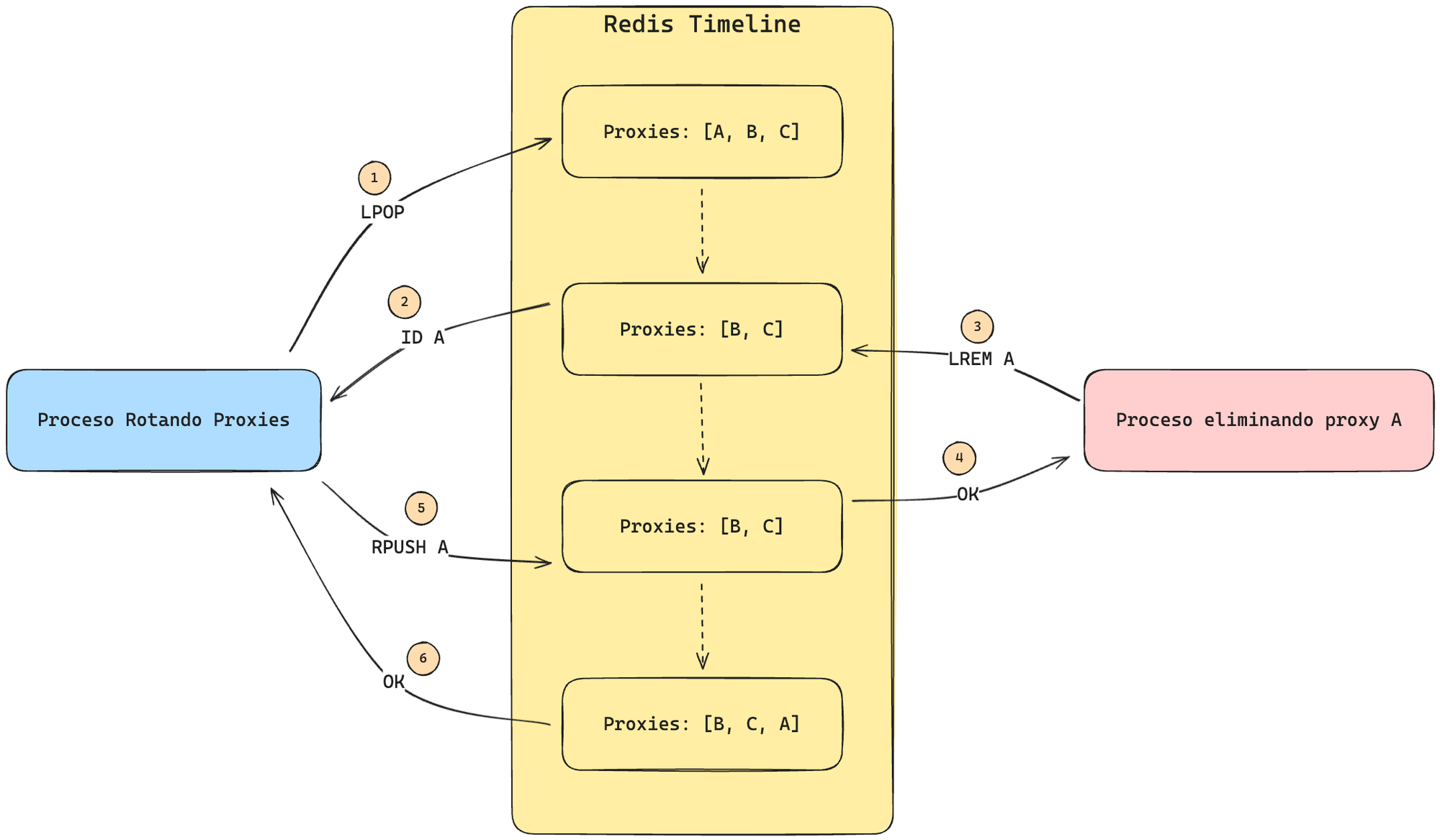
Issue:
Right after proxy A is removed from the circular list (step 2), another process deletes it (step 3).
Because proxy A no longer exists in the list at that moment, Redis confirms the deletion, but then the rotation process adds A back to the list.
Consequence:
- Inconsistency between Redis, PostgreSQL, and Compute Engine.
- Thousands of jobs could fail if they try to use a deleted proxy, since the deletion process would remove the VM from Compute Engine.
Solution: Atomic Redis Operations
Fortunately, Redis provides atomic operations like LMOVE, which allows moving an element between lists without any gaps for conflicting operations.
Data Synchronization Across Systems
We manage three separate data sources, all containing proxy-related information:
- Redis: Stores proxy IDs in circular lists.
- PostgreSQL: Stores detailed proxy data and restrictions.
- Compute Engine: Hosts the actual proxy VMs.
Synchronizing data may seem easy, but it comes with many edge cases. During the creation or deletion of proxies, the three data sources become potential points of failure that need to be managed.
Continuing with the example of proxy deletion, let's consider the following simplified case:
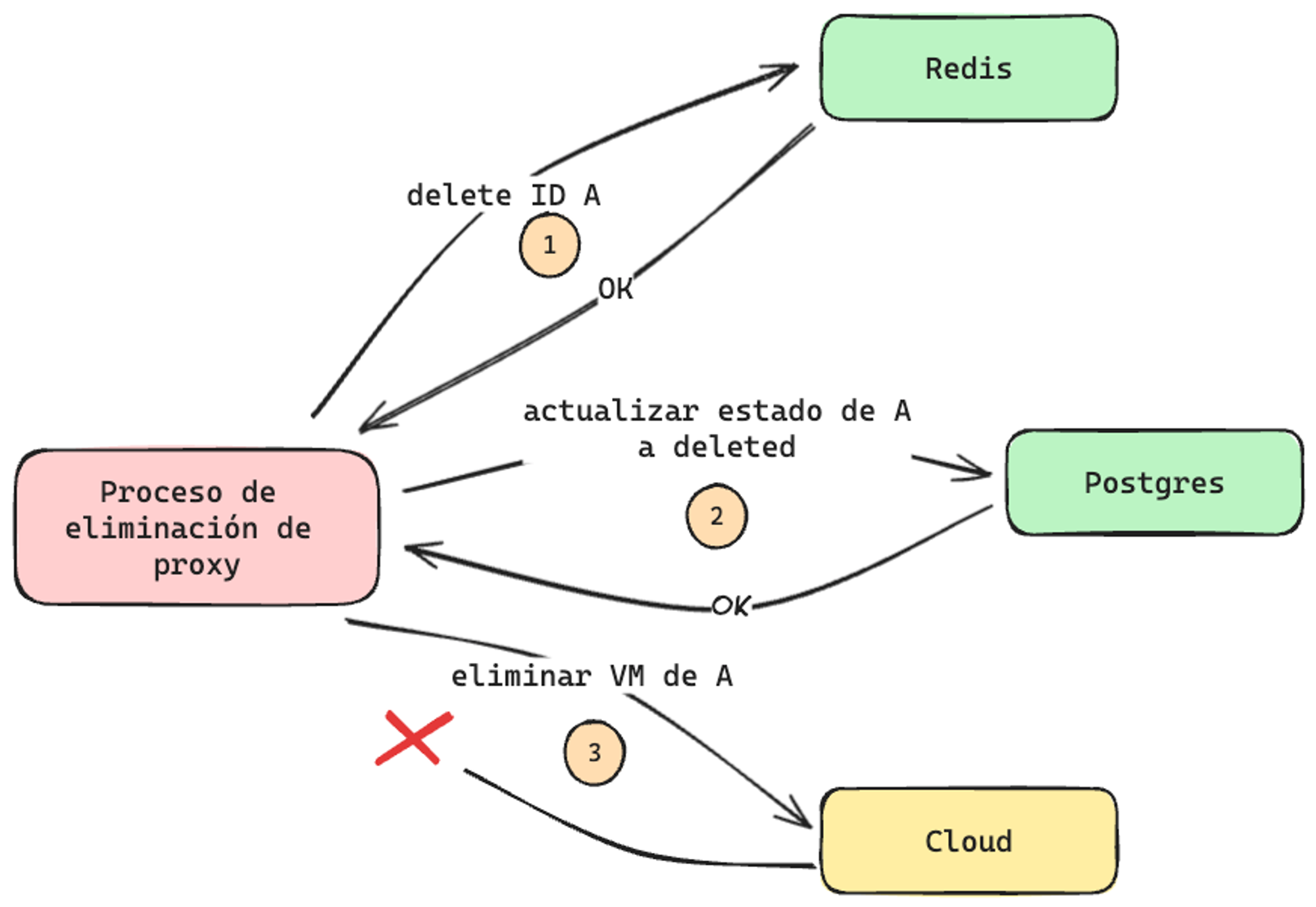
In this case, we successfully deleted proxy A from Redis and PostgreSQL, but we did not receive a response from Cloud, meaning we don't know what happened to the VM. This issue can occur not only in Cloud, but also in Redis and PostgreSQL.
To handle these cases, the first thing to note is that Cloud is the source of truth. Therefore, we can use it to correct incomplete processes with a synchronization job. This job will take a snapshot of the active or inactive proxies in Cloud and update Redis and PostgreSQL accordingly.
Considering the scenario in the image:
- If the VM was successfully deleted, then ✅ the synchronization job will not find it, and everything remains consistent.
- If the VM was not deleted, the synchronization job will recreate the proxy in PostgreSQL and Redis, and the deletion process can be retried later.
Although this process is straightforward, we must be careful with the order of operations: we cannot delete a VM from Cloud if the proxy is still available in Redis, as other jobs might try to use it.
Additionally, we need to ensure that no other process is modifying the same proxy. Consider a scenario where one process is deleting a proxy while the synchronization job is running at the same time:
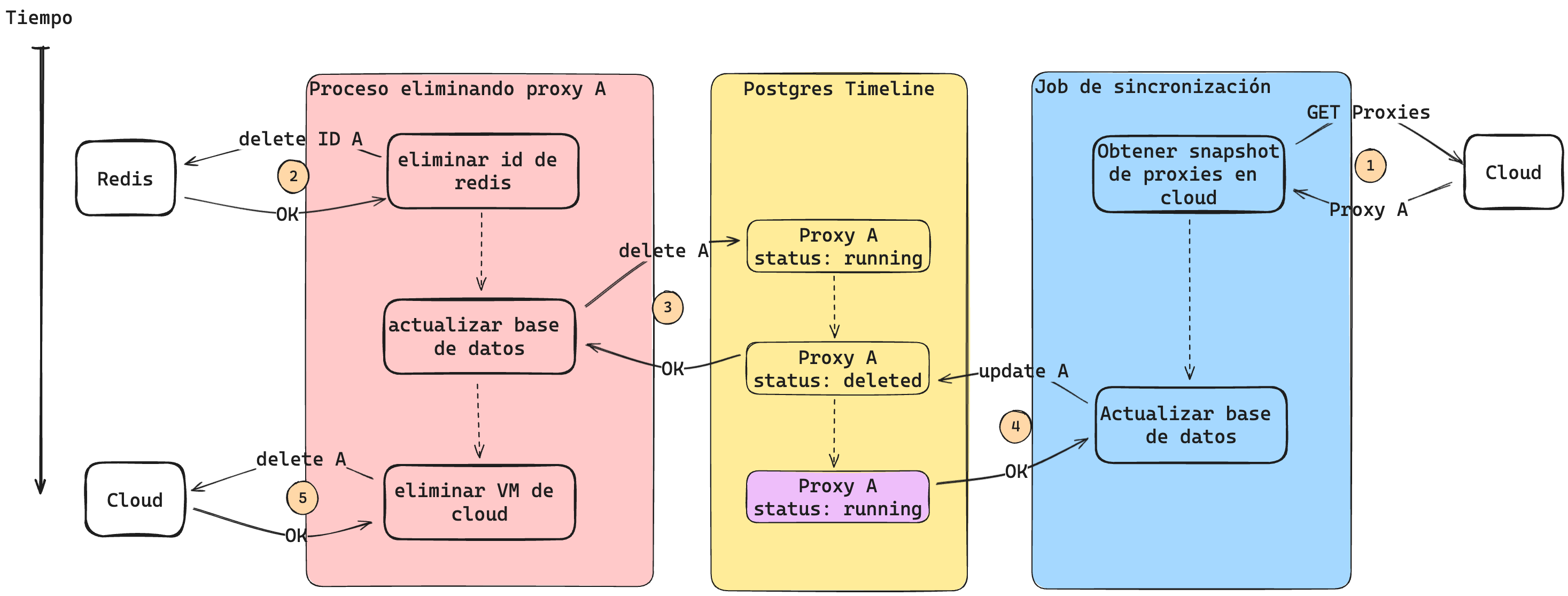
Once again, we encounter a race condition because the last process to update the database is the synchronization job. Note that if we delete the proxy instead of updating its status in step 3, we face the same issue: the synchronization job will recreate the proxy.
Currently, we rely on locks in PostgreSQL to ensure that the process acquiring the lock is the only one modifying the proxy:
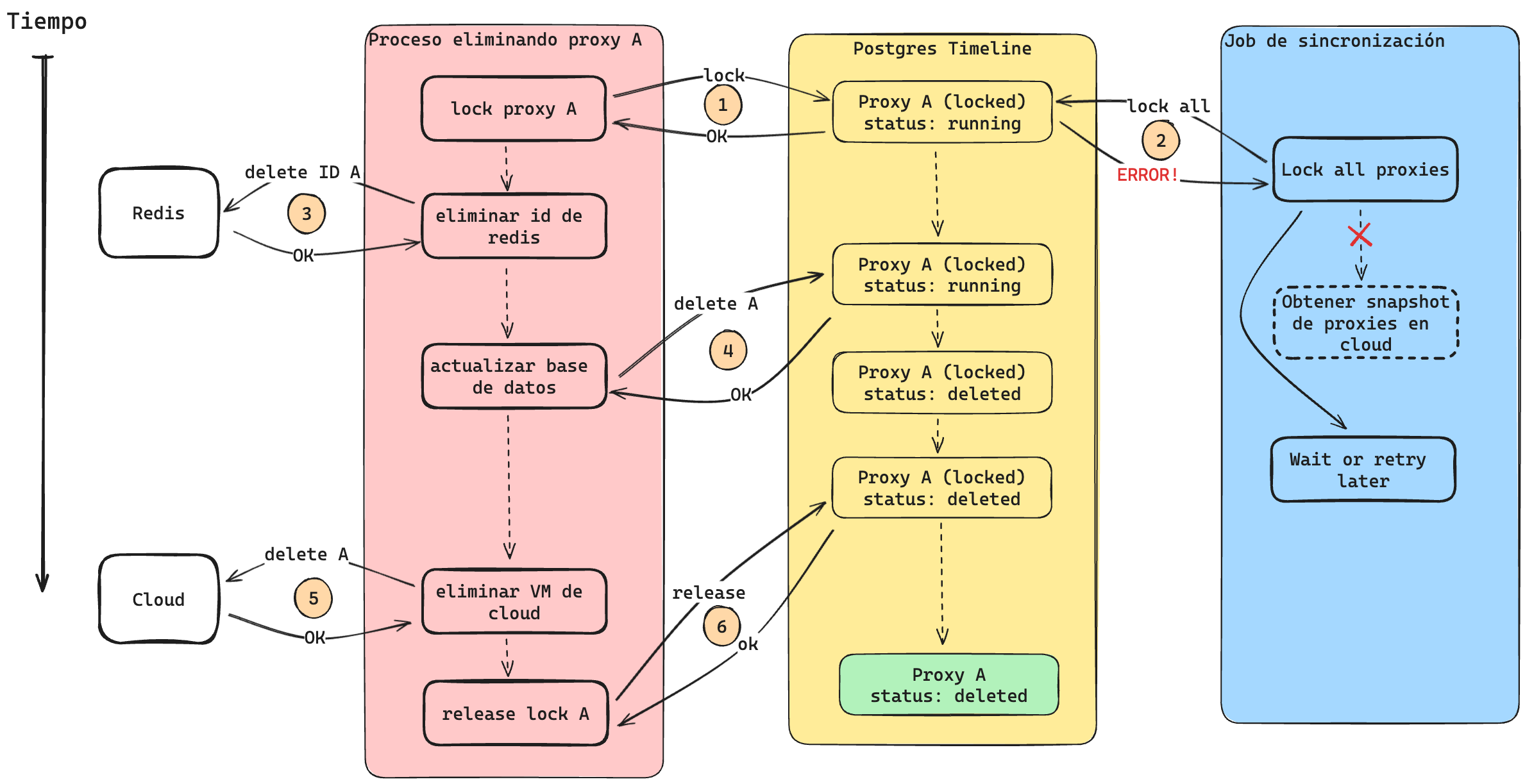
In this case, since the proxy deletion process acquires the lock before the synchronization job, it can proceed knowing that it is the only process modifying the resource.
An interesting aspect is that the synchronization job acquires a lock on all proxies before taking a snapshot of the proxies in Cloud. If we did this afterward, another process could modify a proxy’s state, making the synchronization job’s snapshot outdated.
Here’s an example:
- The synchronization job takes a snapshot of the proxies in Cloud. At that moment, proxy A and B are active.
- A different process marks proxy A as "deleted" in Cloud.
- Since the synchronization job is unaware that A was deleted, it incorrectly marks proxy A as "active" in the database.
This leaves the database in an inconsistent state.
Another issue: in the diagram, an error appears when the synchronization job tries to acquire a lock on the proxies because another process has already locked one of them.
This can be handled in two ways:
- Throw an error if any proxy is being modified (as shown in the diagram).
- In PostgreSQL:
SELECT ... FOR UPDATE OF table_name NOWAIT. - Wait until no proxy has an active lock.
- In PostgreSQL:
SELECT ... FOR UPDATE OF table_name(without NOWAIT).
You can find more details on this in the PostgreSQL documentation.
We generally choose the second option because our locks don’t last long. This way, we avoid implementing complex retry logic, keeping the solution simpler.
These considerations apply not only to proxy deletion but to any operation performed on them.
Final Thoughts
The proxy system evolved alongside Fintoc’s growth. As I mentioned earlier, we start simple and only introduce complexity when it makes sense—and in this case, it made a lot of sense.
While we strive for simple solutions, we pay close attention to edge cases, ensuring we prevent issues related to concurrency and data synchronization.
Even though we’ve come a long way, this project is far from over. As we scale, new challenges arise, like ensuring that the synchronization job doesn’t block critical operations.
🚀 If you love tackling scaling challenges, we're hiring! Check out our open positions and apply here.



.jpg)





.gif)
.gif)